안녕하세요 여러분, 물범쌤입니다 :)
최근, flux라는 모델이 굉장히 주목받고 있어서
한번 소개드렸던 적이 있는데요,
하지만 좋은 품질의 flux에도 몇가지 단점이 있었습니다.
첫번째, 매우 큰 용량
flux 체크포인트의 경우 30GB에 육박하는 용량으로
일반적인 체크포인트 2~3개분의 용량 부담이 있었죠
두번째, 이미지 생성시간
물론 이미지 생성시간은 PC의 사양마다 다르겠지만,
준수한 사양의 PC기준으로 2분내외의 이미지 생성 시간이 소요되었습니다.
사용자가 프롬프트를 추가하거나, 원하는 이미지가 나오는지 확인하기 위해서는
이미지가 제작되기까지 기다리는 시간이
은근히 길게 느껴졌습니다.(한국인이라 그런가...)
세번째, 로라 사용 관련
그래서 지난번 포스팅에서도 지나가는식으로 소개드렸던
NF4 모델을 사용하면 이미지 생성 속도를 월등하게 올릴수 있었습니다만
문제는 NF4모델에서는 로라 적용이 되지 않습니다.
사실 NF4모델이 나온것도 얼마 되지 않았기 때문에
기다리다 보면 그에 관련된 로라모델이 별도로 나오지 않을까 생각합니다만,
벌써 gguf라는 방식의 모델이 또 나온것을 보면
얼마나 사용자들과 개발자들이 현재 flux모델에 관심도가 높은지 실감이 갑니다.
제가 아는것만으로도 거의 일주일마다 새로운 패턴들이 나오는것 같거든요.
뒤쳐지지 않게 잘 따라가야겠죠?
그럼, 본론으로 들어갑니다.
먼저 GGUF라는 말이 뭔지 궁금하신 분들을 위해 설명드리자면
Georgi Gerganov Machine Learning Unified Format 의 약자로서
기존의 모델을 양자화한 방식을 말합니다.
양자화라고 하면 또 생소하시기 때문에 더 쉽게 말씀드리면
기존의 모델을 더욱 압축시키고,
모델이 생성하려던 이미지의 기초 사이즈를 축소시켜서
결론적으로 모델의 용량과 이미지 생성속도를 높이는데에 그 목적이 있습니다.
모델 다운로드:
FLUX.1-schnell-gguf
https://huggingface.co/city96/FLUX.1-schnell-gguf/tree/main
FLUX.1-dev-gguf
https://huggingface.co/city96/FLUX.1-dev-gguf/tree/main
Clip모델
https://huggingface.co/openai/clip-vit-large-patch14/tree/main
https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main

Q. 쌤, 모델 다운로드 받으려고 들어갔는데
Q3,Q8,K 같이 이상한 알파벳들이 적혀있고
모델이 너무 많아요. 뭘 받나요?ㅠ
A.이 설명을 드리기 위해서 링크를 먼저 드렸죠
아래의 표를 잘 봐주세요 :)
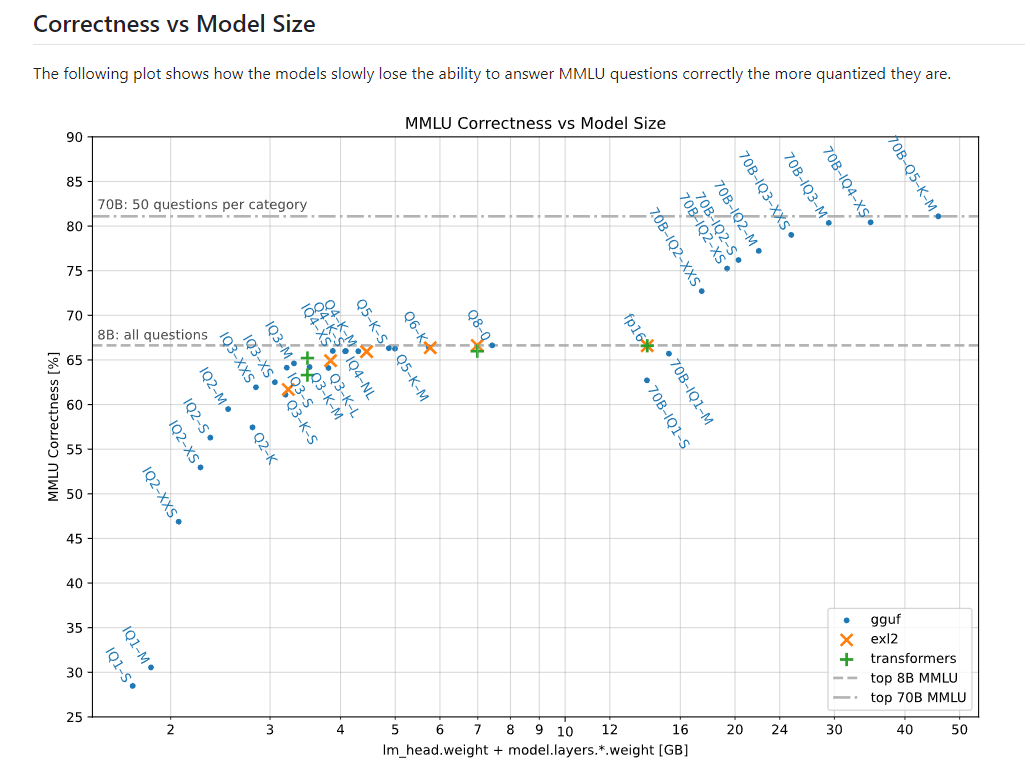
이 표는 gguf의 각 모델이 기존의 모델들과 비교해서
품질과 모델 용량이 어느정도 차이가 나는지 정리되어있는 표 입니다.
중앙에서 살짝 우측을 보시면 fp16이라고 되어있는 곳이 보이시죠?
우리가 기존에 사용하던 flux모델이 fp16이라고 보시면 되겠습니다.
중앙을 기준으로 왼쪽편을 살펴보시면
모델 파일에서 보셨던 Q나 K같은 알파벳들이 보이실텐데요
각 파일들의 성능을 봐주시면 되겠습니다.
예시로, 중앙에서 바로 왼쪽에 있는 'Q8'같은경우,
품질(세로축)은 기존의 fp16과 동일하지만
용량(가로축)은 기존의 모델보다 작은것을 볼 수 있습니다.
사실 그래프로도 보이지만 Q2-k정도 까지 품질이 떨어지는 경우가 아니라면
품질에 대한 손실은 그리 크지 않다고 보시는게 맞습니다.
따라서 PC용량이 작다라고 하시면 Q3 나 Q4정도로,
PC용량도 넉넉하고 품질에 욕심이 난다 라고 하시면
그냥 기존의 flux모델에서 용량만 줄어든 Q8을 사용하셔도 좋습니다.
추천 모델을 한 눈에 알아보기 쉽게 정리드릴게요 :)
(알려드린 링크에는 'Q'모델만 있습니다,
아래 추천 모델에서 알파벳 'Q' 뒤에 붙는 숫자로 판단해주시면 되겠습니다.)
VRAM 8GB 이상:
8B 모델의 Q5_K_S 또는 Q4_K_S
품질 손실이 적으면서도
크기가 작고 중간 사양의 GPU에서도 잘 구동됩니다.
VRAM 4-6GB:
8B 모델의 IQ4_XS or IQ3_M
크기가 더 작기에 제한된 VRAM에서도 구동하며,
여전히 괜찮은 성능을 보여줍니다.
VRAM 4GB 미만:
8B 모델의 IQ2_M 또는 IQ2_S
품질 손실이 더 크지만,
극히 제한된 PC환경에서도 구동할 수 있습니다.
CPU만 사용 가능:
8B 모델의 IQ2_XS 또는 IQ2_XXS
품질과 성능은 크게 떨어지지만,
GPU 없이도 모델을 실행할 수 있습니다.
추가로, flux 로라 모델 같은 경우는
지난번 포스팅에서 알려드렸던 사이트에서 받아주신 모델을
그대로 사용하시면 됩니다 :)
https://healtable.tistory.com/47
※주의사항입니다.
다운로드 받은 gguf 파일들은 체크포인트 폴더에 추가하시면 안됩니다.
gguf 파일들은 *\ComfyUI\models\unet 폴더에
clip파일들은 *\ComfyUI\models\clip 폴더에 넣어주세요 !
(*은 comfyUI설치경로입니다. 사용자마다 다르겠죠?)
자 그러면 바로 적용을 해볼건데요,
ComfpUI로 접속하셔서
먼저 다운로드 받아줄 커스텀 노드가 있습니다.
GGUF모델은 기존의 체크포인트 로더나 모델 로더로 적용할 수 없습니다.
Unet Loader라는 별도의 노드로 적용할 수 있기 때문에
위의 커스텀 노드를 꼭 받아주셔야 합니다.
GGUF 노드를 설치하셨다면 살짝한 노드를 수정해주시면 되는데요
기존의 체크포인트 노드 대신, gguf 노드를 추가해주세요

전체적인 노드는 아래와 같습니다.
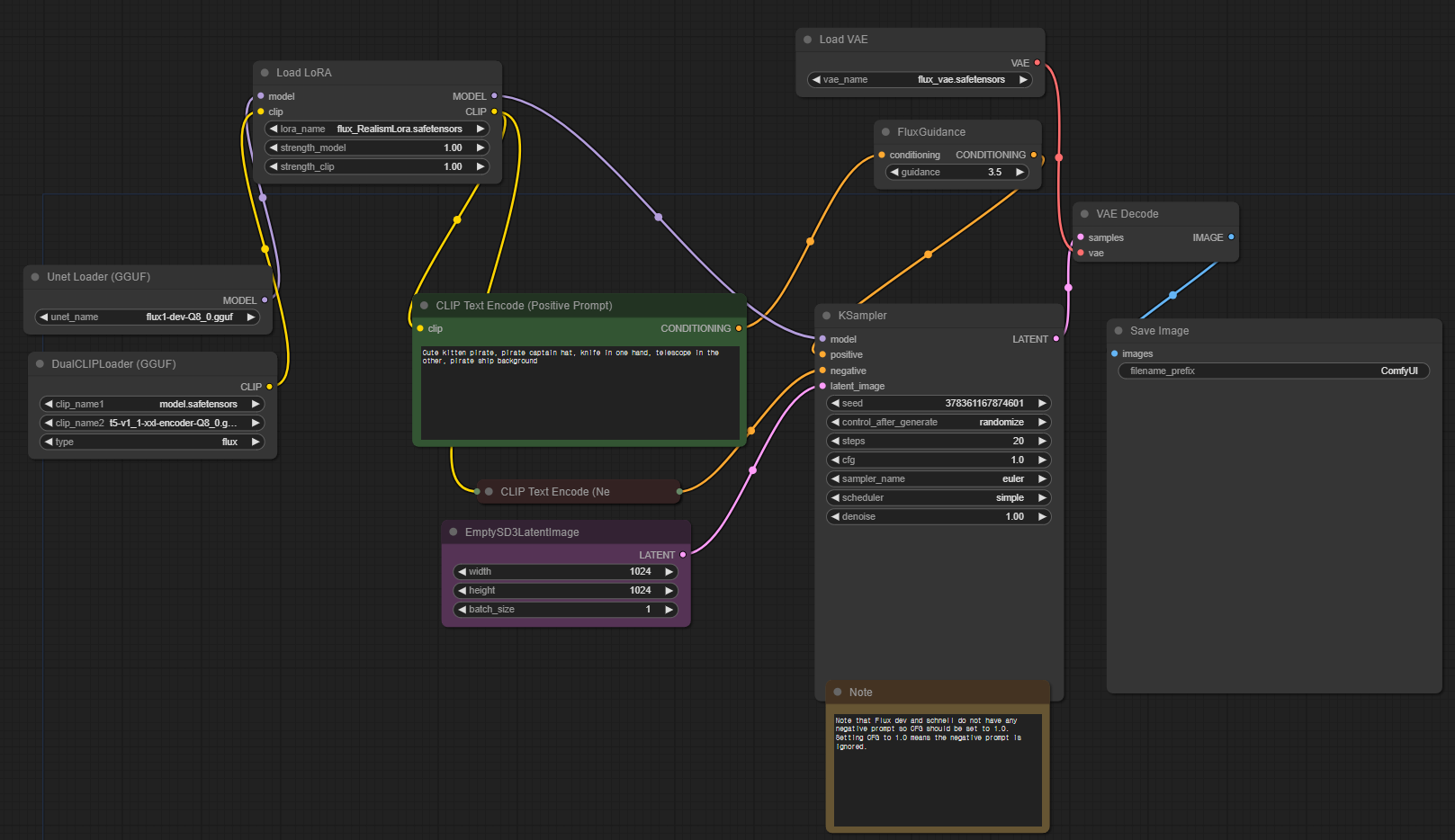
이제 로라가 제대로 적용되는지 봐볼까요?
간단한 프롬프트를 넣어서 한 번 비교해 보겠습니다.

로라 부분 이후의 노드들을 복붙(Ctr+c,Ctr+v)해서, 노드를 가르고,
한쪽은 리얼리즘 로라를, 다른 한쪽은 미드저니 버전의 로라를 입력했습니다.
시드값은 모두 픽스로 고정했기 때문에
두 이미지의 로라를 제외한 설정값은 모두 동일합니다.

어떤가요?
로라가 적용되어서 두 이미지의 분위기가 많이 다른것을 알 수 있습니다.
사용해본 바로는 NF4를 따라잡을 만큼 이미지의 생성속도가 올라가진 않았지만
그래도 기존의 Flux보다는 많이 개선되었다는 점이 체감되었습니다.
속도가 중요하고 테스트 해볼때에는 NF4,
그리고 복잡한 프롬프트와 로라의 필요성이 느껴지는 이미지는
gguf를 사용하게 될 것 같네요 :)
마지막으로 Q5모델과 Q8모델의 품질차이도 보여드리고 마무리 하겠습니다.


오늘은 최근 가장 주목받는 모델인 Flux의 새로운 방식, gguf를 알아보았습니다.
이 컨텐츠가 유익하셨다면
커피값은 기업들에게 받을테니
광고 한번씩만 눌러주시면 감사드리겠습니다 :)
그럼 모두 좋은 하루 되세요! ^^
'스테이블 디퓨전(StableDiffusion)' 카테고리의 다른 글
| 이미 생성된 이미지의 표정을 바꿔봅시다(ALP) (2) | 2024.09.04 |
|---|---|
| Flux보다도 텍스트를 더 잘 표현하는 AI (5) | 2024.08.29 |
| 이미지가 프롬프트라고?(Img2Img 아님) (0) | 2024.08.23 |
| 요즘 주목받는 Flux 를 아시나요? (1) | 2024.08.19 |
| 로라(Lora)를 만들어 봅시다. (3) | 2024.08.03 |